Рефераты и научные статьи очень часто размещены в интернете в формате PDF. Чтобы оттуда что-то позаимствовать, нужно открыть исходный файл, вручную выделить несколько страниц, скопировать, открыть ваш текстовый документ, вставить скопированное. Несложно, но много рутины. В редакторах «Р7» всё можно сделать удобнее.
Новый плагин
Опытные пользователи наших редакторов знают, что в редакторах «Р7-Офис» давно существует встроенный плагин для распознавания текста на популярном движке Tesseract с открытым исходным кодом. У него были свои недостатки, например не всегда корректное распознавание при низкой контрастности (мелкий бледный текст на сером фоне). Если источник был на разных языках, нужно было проводить распознавание для каждого отдельно, указывая вручную. А самое главное, что ему можно было «скормить» только изображения и только по одному.
Новый «Плагин для распознавания текста и вставки текста в документы для Р7-Офис» (OptiReader) предлагает работать с различными источниками, включая многостраничные документы Adobe Acrobat (pdf) и наборы изображений в форматах png, gif, jpg. Слово «наборы» означает, что вы сможете загрузить сразу по несколько картинок.
Чтобы воспользоваться новинкой, сначала ее нужно установить. Заходим на страницу плагина на нашей витрине, нажимаем «Скачать плагин». Вы загрузите архив zip, который нужно распаковать.
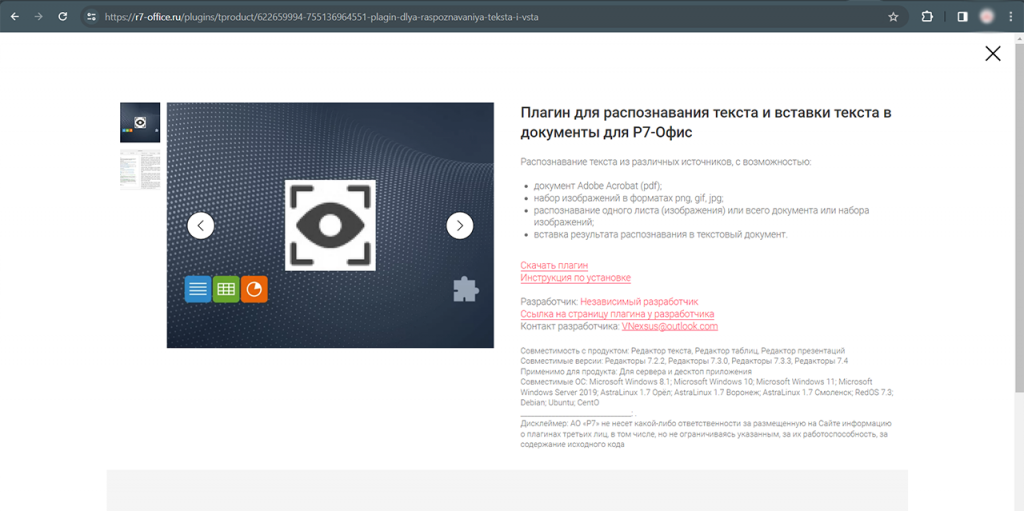
После этого в любом настольном редакторе «Р7» заходим на вкладку «Плагины» и нажимаем кнопку «Настройки».
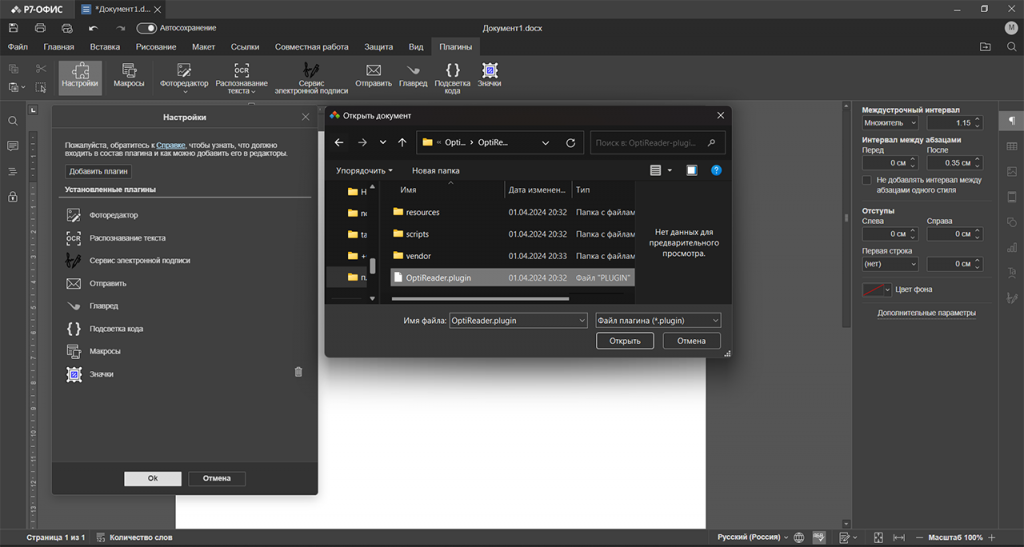
В открывшемся окне нужно нажать кнопку «Добавить плагин», указать расположение файла OptiReader.plugin и не забыть про ОК.
На верхней панели инструментов появляется кнопка OptiReader. При нажатии на нее открывается большое окно. Вы можете перетащить файлы прямо сюда мышкой или кликнуть, чтобы открыть системное окно, в котором можно будет указать путь к файлу или нескольким файлам сразу.
Тестируем на картинках
С прошлого раза у нас остались тестовые картинки с разными фонами, форматированием, языками и цифрами. Загружаем сразу два изображения – он отображаются по одной, можно листать их стрелками. Захотели добавить картинку – нажмите кнопку «Выбрать файл».
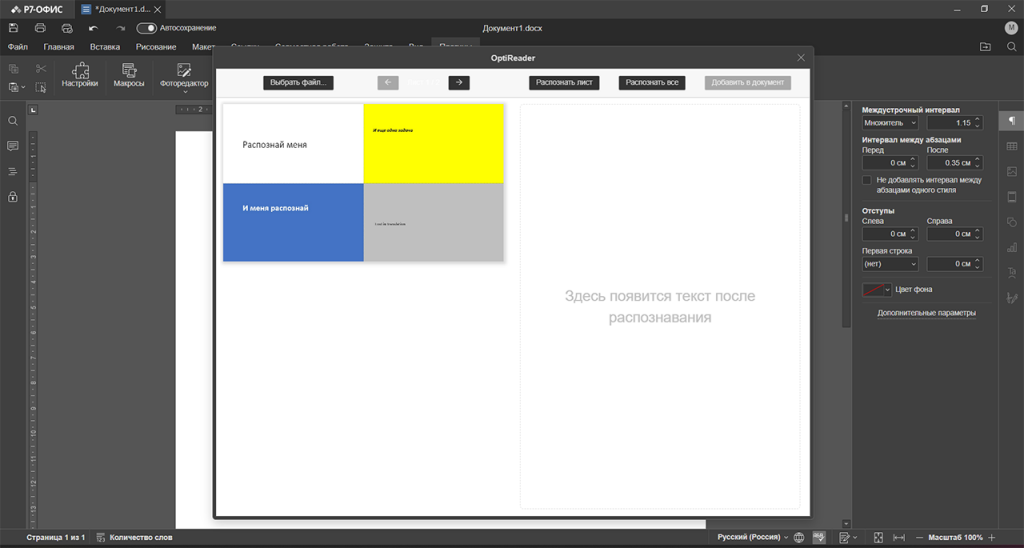
Вверху вы можете видеть кнопки «Распознать лист» и «Распознать всё», название которых говорит само за себя. Если текст большой или картинок много процесс распознавания может занять некоторое время. В этом случае вверху появляется шкала прогресса. В нашем случае всё произошло мгновенно, после чего стала активной кнопка «Добавить в документ». Результат распознавания вы можете видеть на экране
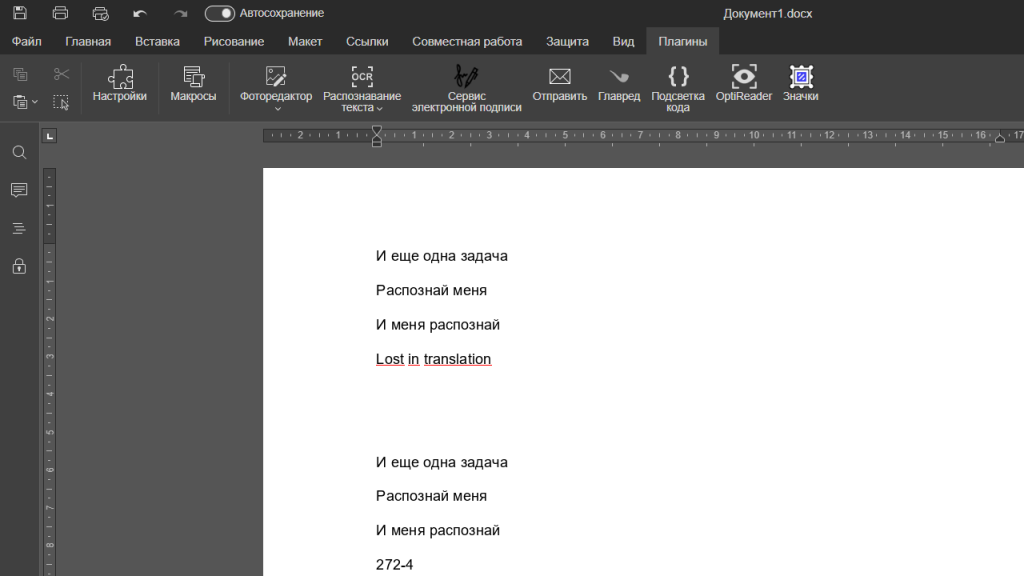
У нас были две похожих картинки. Текст с них расположен двумя блоками. Размер шрифта, контрастность и язык на результат не повлияли, а вот с арифметическими знаками плохо – имейте это в виду и лишний раз проверяйте математические выражения. Вообще проверка результата никогда лишней не будет.
Тестируем на PDF
Вот мы и добрались до операции, которая внесена в заголовок этой статьи. Все шаги аналогичны описанным выше: отрываем или перетаскиваем исходник в окно, распознаем всё и вставляем в документ.
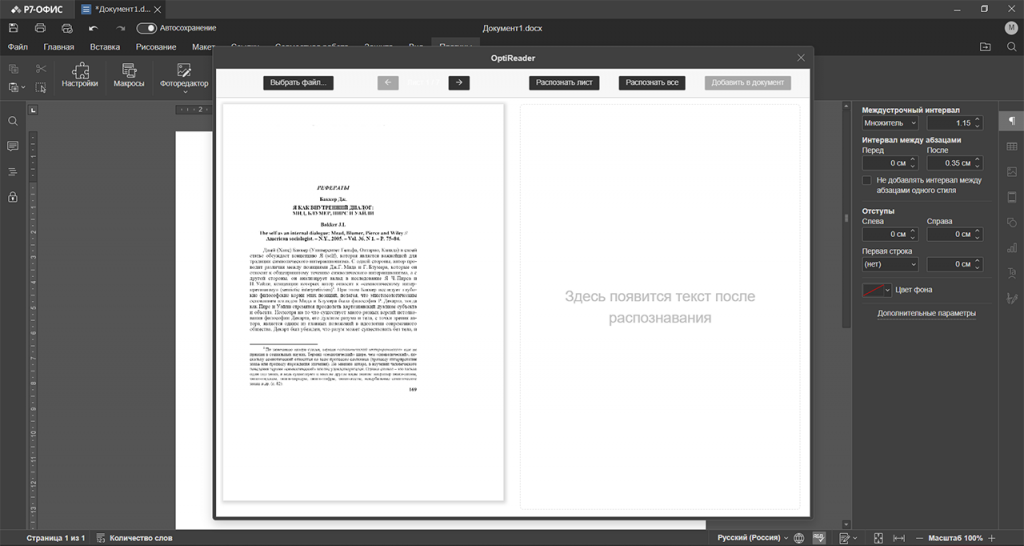
Для примера мы скачал реферат из интернета. Это хороший тест средней сложности. Здесь не самая привычная вёрстка, есть сноски, разное форматирование текста, помимо русского и английского шрифта есть еще и немецкий.
Результат распознавания вы видите ниже. Некоторые вещи нужно поправить (инициалы превратились в цифры, знаки переноса стали дефисами), но это стандартная практика. Обойтись совсем без подчисток вам удастся только в случае очень простых исходников. В данном случае мы получили результат высокой готовности для дальнейшей работы с текстом.
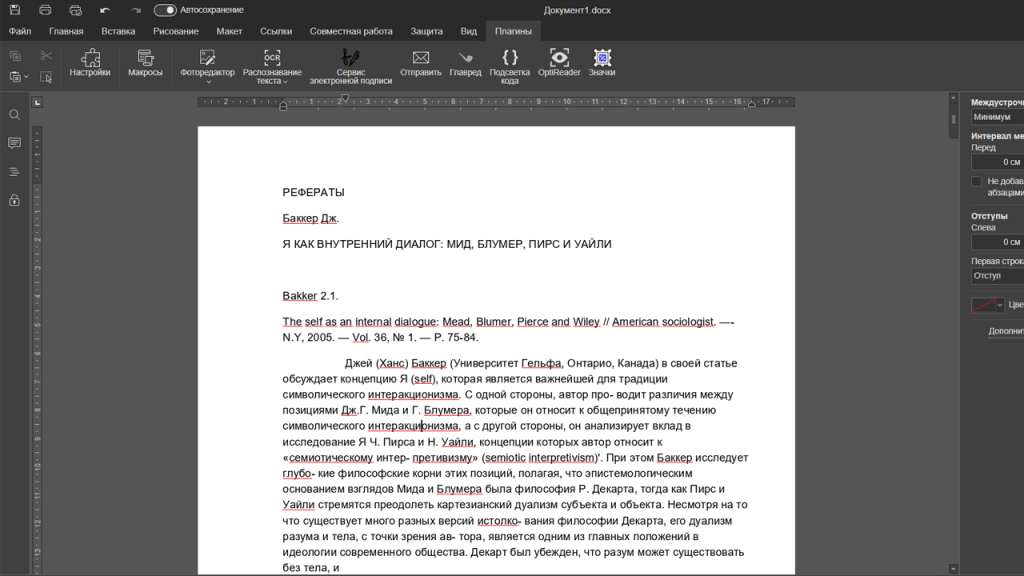
Продвинутый пользователь может спросить, почему нельзя просто отрыть PDF в текстовом редакторе «Р7», сохранить как Office Open XML и снова открыть в редакторе. Давайте попробуем и посмотрим.
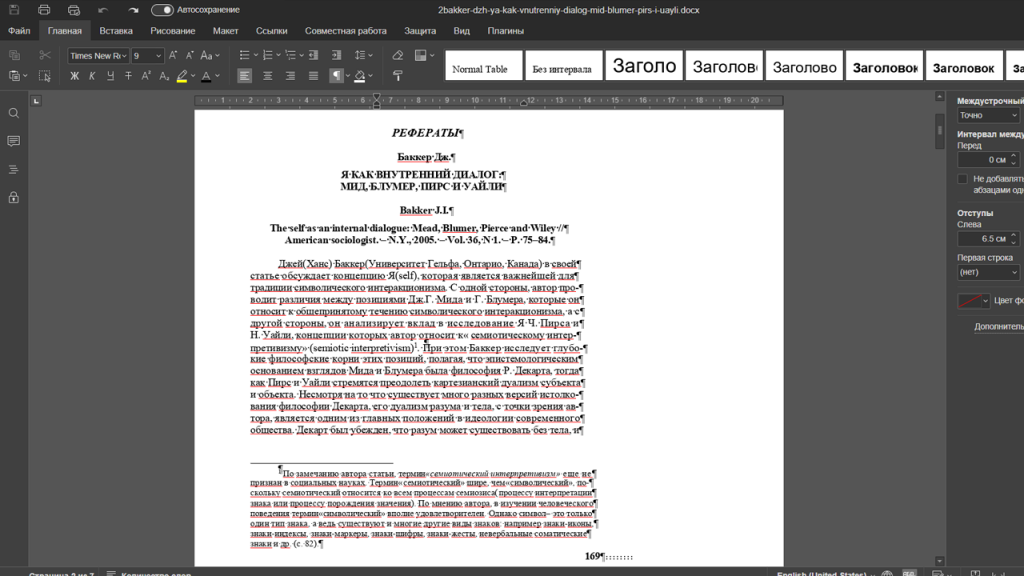
Сходу видится только одно преимущество перед распознаванием: все инициалы верны. Но минусов явно больше:
- Полностью сохранено исходное форматирование из-за чего появились огромные поля, бесполезные графические элементы, лишние нечитаемые знаки.
- Каждая строка заканчивается абзацем и даже с помощью автозамены превращать каждый параграф в единый кусок текста придется долго.
В данном случае нам еще повезло с тестовым документом. Бывают PDF, в которых при пересохранении слетает кодировка, вместо букв начинают вылезать цифры и спецсимволы – в этом случае на редактирование приходится тратить очень много времени.
В любом случае хорошо, что у вас есть разные инструменты на выбор и вы можете использовать тот, который считаете более подходящим.
Если вас заинтересовали плагины, вам могут быть интересны другие посты на эту тему:
- Это вообще законно? Открываем вложенные в документ файлы
- Ой, я куда-то нажал: как заблокировать переход по ссылкам в документе
- Специальные возможности для администраторов в крупной компании
Понятно, что уже весна и хочется подышать свежим воздухом, но если вы хотите получить больше информации, то можете воспользоваться рубрикатором и поиском, которые расположены справа от этого текста, посмотреть популярные и похожие статьи. Помимо этого у нас на сайте есть база знаний в карточках, а еще много увлекательного контента в VK и в Telegram. Там же есть возможность написать нам, поделиться своим опытом и задать вопросы. А еще вы можете задавать свои вопросы нашему боту Лёлику и сразу получать ответы. Попробуйте сами!