Помните, у нас был текст про обманчивую простоту СОРТ и ФИЛЬТР. На самом деле сегодняшняя статистическая функция нередко упоминается в связке с ними через запятую. Если у вас большая таблица и вы хотите понять, а сколько вообще уникальных значений, строк или столбцов, то УНИК выдаст их вам отдельным массивом. Это могут быть цифры или текст, одиночные значения или пары.
Синтаксис функции
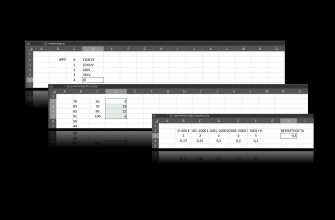
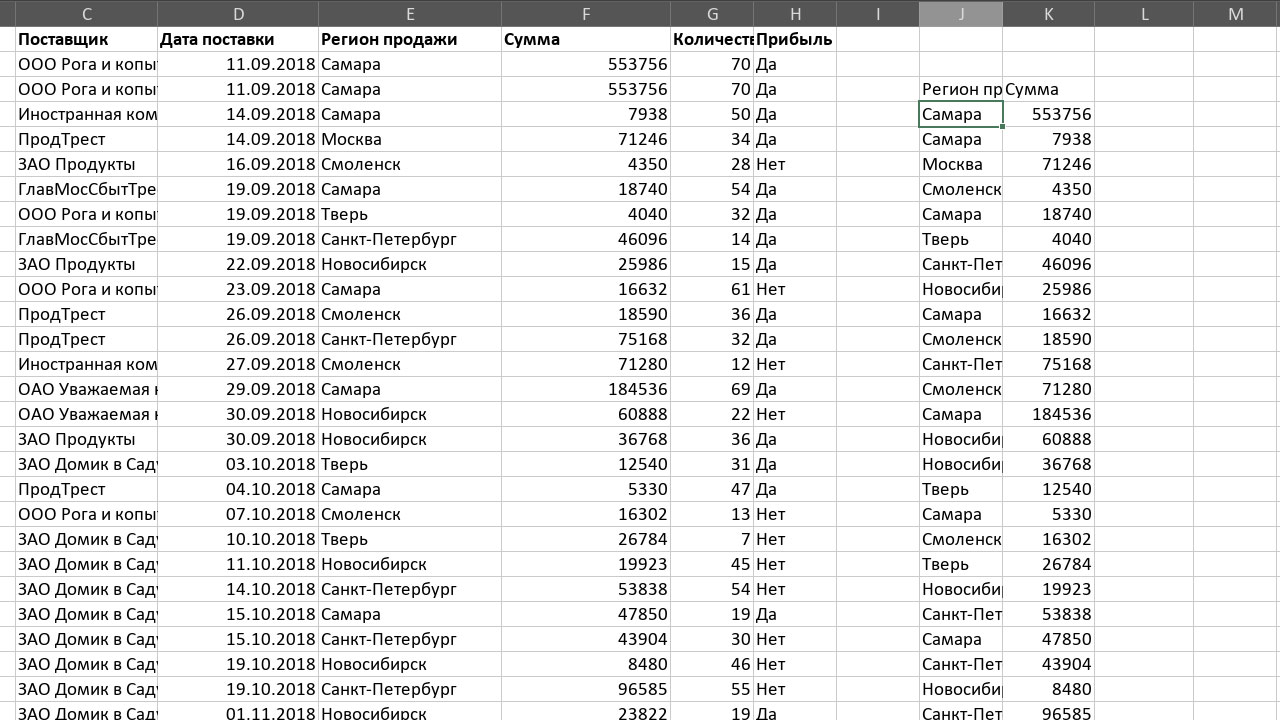
Начнем с примера, возьмем нашу обычную тестовую таблицу и введем функцию в самом коротком варианте, просто указав диапазон, который мы рассматриваем. Это функция массива, так что не забываем про ввод с помощью Ctrl+Shift+Enter. Получим следующий результат. Выглядит так, будто мы просто скопировали ячейки, но нет. Для наглядности мы специально продублировали первую строку. И в выдачу она не попала. Соответственно, если где-то там внизу в гуще данных на двухсотой или трёхсотой строке снова будет задвоение, оно будет проигнорировано.
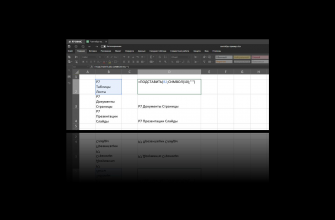
Синтаксис функции УНИК выглядит следующим образом:
=УНИК(массив,[по_столбцам],[только_один_раз])
Первый аргумент обязателен, два других – не обязательные:
- массив – все ячейки, в которых мы ищем уникальные значения,
- по_столбцам – определяет метод сравнения: столбцы (ИСТИНА) или строки (ЛОЖЬ, по умолчанию),
- только_один_раз – определяет метод возврата: ИСТИНА для единичных значений, ЛОЖЬ – для уникальных.
По умолчанию на второй и третьей позиции всегда ЛОЖЬ, то есть сравниваем строки, ищем уникальные.
Варианты использования
На самом деле самым простым было бы выбирать уникальные значения из одного столбцы или строки, например, в нашем случае получить перечень городов (его при желании можно сразу отсортировать с помощью СОРТ: =СОРТ(УНИК(…))).
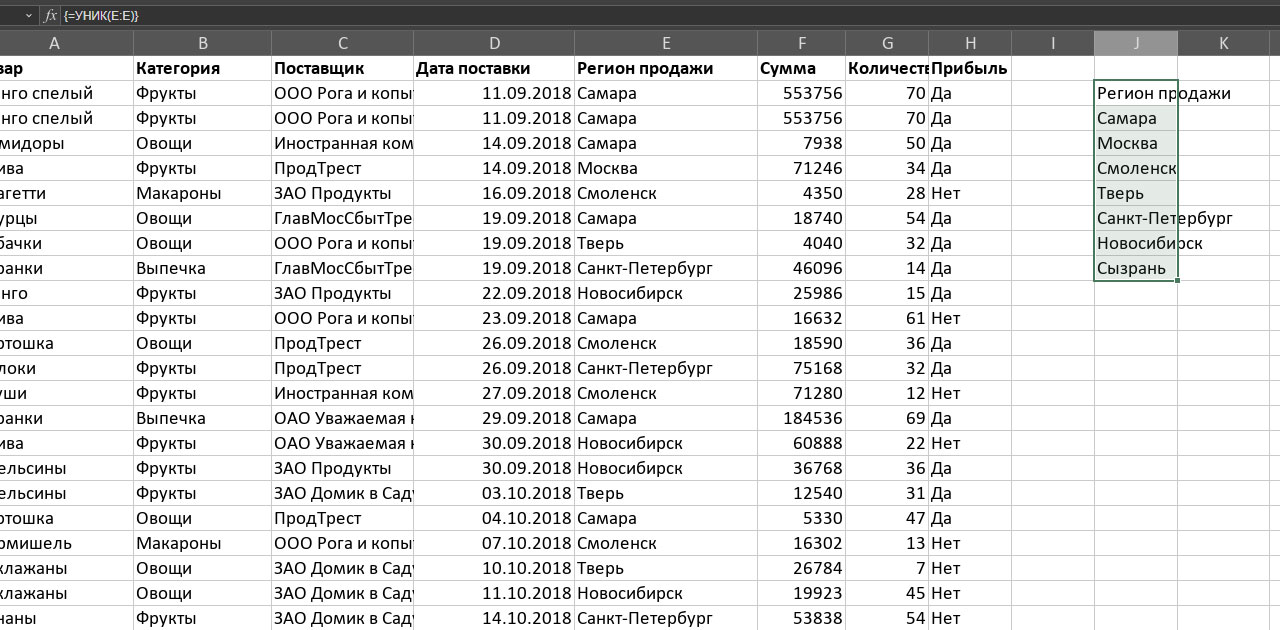
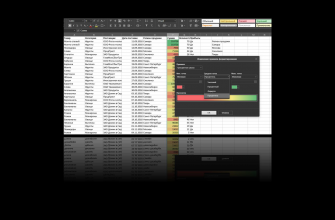
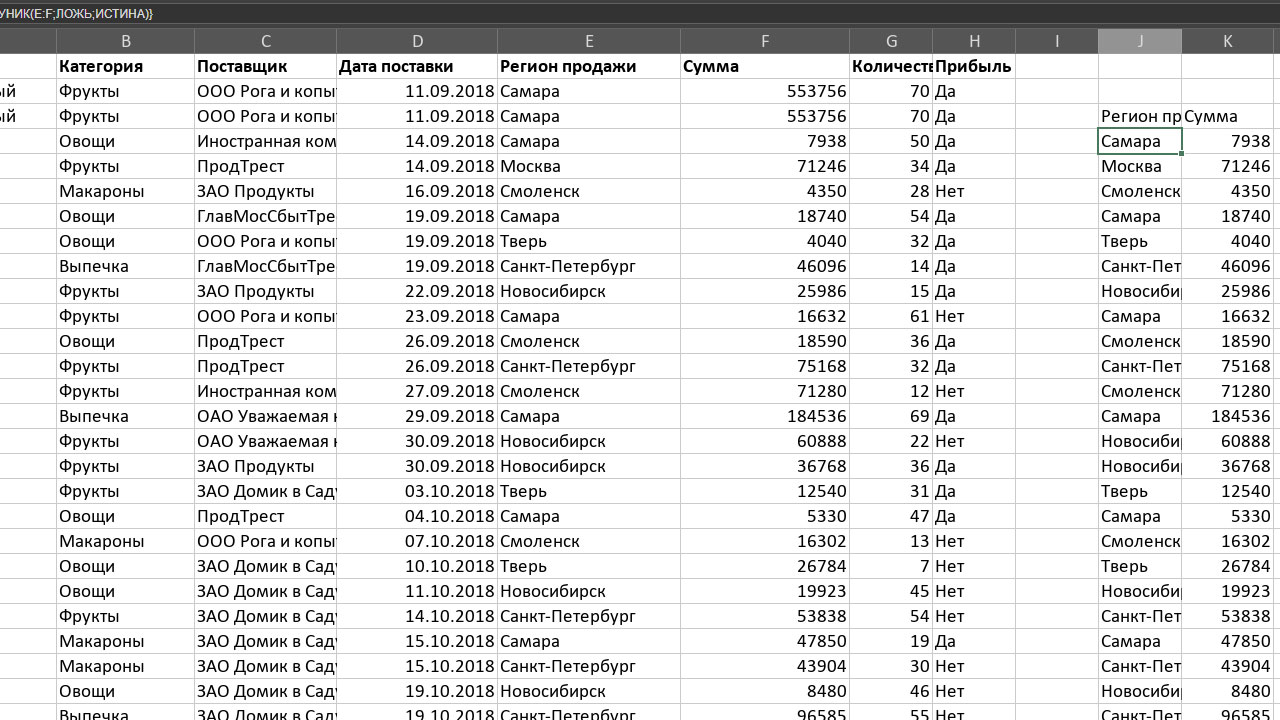
Но давайте всё-таки вернемся к более заковыристым случаям. В самом первом примере мы убрали продублированные строки: если было несколько одинаковых, оставляли одну. Теперь оставим только те, которые встречаются один единственный раз. Формула будет выглядеть так: =УНИК(E:F;ЛОЖЬ;ИСТИНА), а результат – как на снимке экрана ниже. Когда это может пригодиться? Когда повторяющиеся строки – норма, а единичные аномалия. Если бы у нас вместо поставок еды была таблица с платежами клиентов, то клиенты заплатившие один раз, – это сегмент, с которым нужно работать отдельно. И его нужно вычленить.
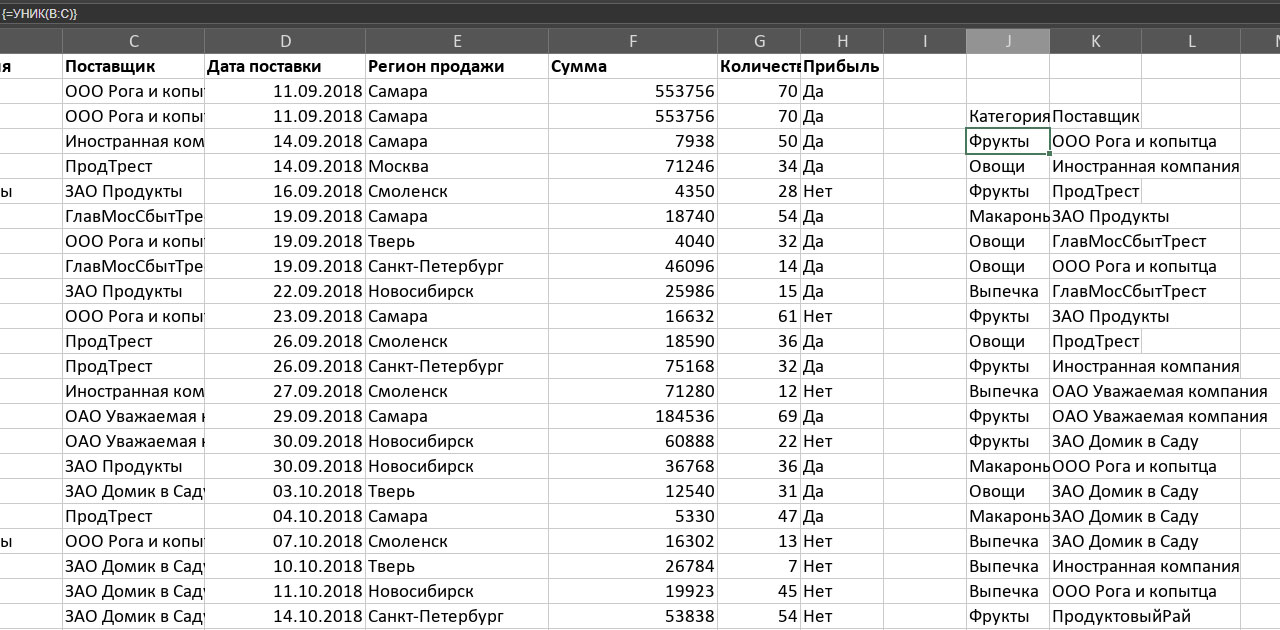
В городах и ценах было сильное разнообразие изначальных данных и ценность функции не так очевидна. Давайте попробуем ее применить к категориям товаров и поставщикам, которых заведомо меньше. Вернёмся к самому короткому варианту формулы и получим уже достаточно обозримый список на два десятка строк.
Примечание. Мы чаще пользуемся вертикальными таблицами, поэтому по умолчанию сравниваем по строкам. Если вы работаете с горизонтальной таблицей, то измените второй аргумент на ИСТИНА.
Пожалуй, на этом всё. Но если вы готовы дальше погружаться в тему таблиц, предлагаем похожие посты.
Если вы хотите получить больше информации, то можете воспользоваться рубрикатором и поиском, которые расположены справа от этого текста, посмотреть популярные и похожие статьи. Помимо этого, у нас на сайте есть база знаний в карточках, а еще много увлекательного контента в VK и в Telegram. Там же есть возможность написать нам, поделиться своим опытом и задать вопросы. А еще вы можете задавать свои вопросы нашему боту Лёлику и сразу получать ответы. Попробуйте сами!